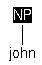
 Internal Structure
Internal Structure|
Internal Structure |
 |
 |
|
| General Features: | Positional Features: |
| Agreement Processing: | Indexing: |
(*) Not actually described here. Reference is to internal structure predicates.
cat(X,C)
|
Category label of constituent X is C
|
Note there are no mode restrictions on cat. Examples:
| Goal | Bindings | Notes | |
| (a) | cat([NP John],C) |
C = np |
|
| (b) | cat(X,np) |
X = [NP...] |
X is instantiated to be a new constituent with
category label np. Other features and (possible)
subconstituents are unspecified.
|
| (c) | cat(X,C) |
X = [C...] |
As above, except the category label C
remains unbound. |
| (d) | cat([NP John]) |
None | Checks for constituenthood. |
In (b) and (c) above, cat/2 is being employed as a partial
constructor.
For convenience, cat/1 can be used in its place when the
category label is not required - e.g. to check for constituenthood as
in (d) or to instantiate a new constituent.
References: Implementation Notes
+X has_feature +F
|
Holds if constituent X has feature F
|
Basic Features
In general, features may be simple or complex. For example, consider the empty object of see in the following excerpt:
 |
| (a) Whom do you think that John saw? |
Here, simple atoms like apos and gamma are
used as features to indicate that the empty object is both in an
A-position and gamma-marked.
A complex feature structure, chain/3, is used to
hold movement chain information. This feature has three slots
indicating that this empty category is a base trace
( last ), that its antecedent is NPt[1], and
that [[vp,i1,i2,c1],[]] represents the path leading up to
NPt[1].
Of course, complex features need not be ground. Note the Case
feature contains a slot with a variable ( _0 ). The verb
see normally assigns accusative Case to its object. However,
given Case transmission, the Case slot of the head of the entire
chain, namely whom (not shown here), gets the value
acc instead and the Case slot of the trace left behind is
unbound.
In general, there are two standard modes of usage with X
has_feature F. It can be used to further instantiate
underspecified feature values as well as to perform simple look up as
shown below. In other words, F will be unified with a
matching feature. Here, we use NPt-A-P[1] to refer to the
empty object of see from (a):
| Goal | Result/Bindings | |
| (b) | NPt-A-P[1] has_feature gamma |
Succeeds / None |
| (c) | NPt-A-P[1] has_feature adjunct |
Fails / Not applicable |
| (d) | NPt-A-P[1] has_feature case(acc) |
Succeeds / _0 = acc
|
| (e) | NPt-A-P[1] has_feature a(+) |
Fails / Not applicable |
Although has_feature can instantiate feature slots, as in
(d), it cannot be used to add a new feature to a
constituent. (The predicate addFeature
can be used for this purpose instead.) The feature lookup mechanism is
designed to be deterministic (except with respect to active features -
to be described below). This implies that multiple occurrences of the
same feature will be matched just once. In the case of ambiguity
caused by addFeature augmenting the feature list with
additional possible matches, the most recently added version of the
feature has priority. This behaviour allows features to be superceded
or overridden when necessary. For example:
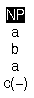 |
 |
addFeature(c(+),[NP]) |
|
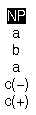 |
| (f) | (g) | |||
| Goal | Result/Bindings | |
| (h) | [NP] has_feature a |
Succeeds once / None |
| (i) | [NP] has_feature c |
Fails / Not applicable |
| (j) | [NP] has_feature c(+) |
Succeeds once / None |
| (k) | [NP] has_feature c(-) |
Succeeds once / None |
| (l) | [NP] has_feature c(X) |
Succeeds once / X = + |
Specialty Features: oneof/2
Some support is provided for encoding exclusive-or disjunction within
a constituent's feature set. The oneof feature when
accessed through has_feature may be used to select and
commit between mutually disjunctive sets of features. In general, we
have the following form:
| (m) |
oneof(_,[[+F(1)1,..,+F(1)n1],..,[+F(m)1,..,+F(m)nm]])
|
If predicate has_feature is called, say, to look up feature
F(1)1, it will not only succeed but
also commit the feature set to contain all the other features in that
set. That is, for subsequent lookups, has_feature will
also hold for all F(1) features, but
crucially not for any from the alternate feature sets
F(i>1).
Implementation Note: Once an initial selection has been made, the
anonymous variable that is the first parameter of oneof
will be bound to the selected feature set. In PAPPI, this is indicated
using the oneis feature in the display. See examples (s) and (t) below.
Example
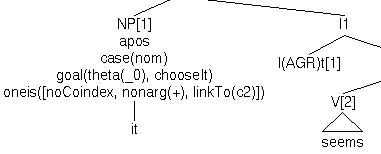
Consider the following combined lexical entry for pleonastic and pronominal it:
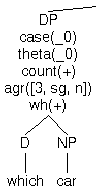
| (n) | lex(it,n,[agr([3,sg,n]),goal(theta(R),lambda(X,chooseIt(R,V,X))), oneof(_,[[noCoindex,nonarg(V),linkTo(c2)],[a(-),p(+)]])]). |
(As an aside, the goal/2 feature that wraps around the
entry's theta slot is used to select between the two senses of
it. Basically, after theta-role assignment, if the theta slot
is instantiated, it must be the pronominal. Otherwise, it's the
non-argument. The general semantics of goal/2 will not be
discussed here, but in the next section.)
The predicate has_feature will have the following
behaviour:
| Goal | Result/Bindings | |
| (o) | [NP it] has_feature agr(AGR) |
Succeeds / AGR = [3,sg,n], no selection
made |
| (p) | [NP it] has_feature p(+) |
Succeeds / Feature set is now [agr([3,sg,n]),goal(..),a(-),p(+)] |
| (q) | [NP it] has_feature nonarg(+) |
After (p): Fails / Not applicable |
| (r) | [NP it] has_feature nonarg(+) |
Before (p): Succeeds / Feature set is now [agr([3,sg,n]),goal(..),
|
Examples:
 |
| (s) It seems that John is happy |
 |
| (t) It is happy |
Specialty Features: goal/2
Finally, in general, features can be active or passive. So far, we
have only seen passive features. Active features are features
with an embedded Prolog goal to be executed whenever the feature is
referenced via has_feature. In general, active features
will have the form:
| (u) |
goal(+Feature,+Goal)
|
Example:
Consider the following lexical entry for the genitive personal pronoun his:
| (v) |
lex(his,n,[morphC(gen),goal(a(A),invPlusMinus(A,P)),p(P),
agr([3,sg,m])]).
|
a(�) and p(�) are used to encode
the Binding-theoretic features �anaphoric and �pronominal,
respectively. Now, let's assume a theory in which English genitive
pronouns behave either like pure anaphors, i.e. have features
a(+) p(-), or pure pronouns, i.e. a(-) p(+),
but not both or neither at the same time. The cost of two separate
lexical entries can be avoided by allowing Binding-theoretic features
to be contextually determined by Binding conditions A (for anaphors)
and B (for pronouns). All we need is the right constraint for these
two features.
Let's associate the predicate invPlusMinus/2 with the
feature a(A). The goal invPlusMinus(A,P)
will be invoked whenever the anaphoric feature is accessed. Its job
will be to constrain A and P to be set to
inverse or opposite values. Assuming conditions A and B are
co-operative, this scheme works because if his is locally
A-bound, it will satisfy condition A - which will set
a(+). This will trigger the goal
invPlusMinus(+,P) which will bind P to
-. On the other hand, condition A will set
a(-) if his happens not to be locally
A-bound. This will trigger P to be bound to
+. For example:
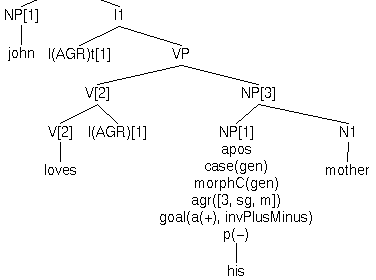 |
 |
| (w) John1 loves his1 mother | (x) John1 loves his4 mother |
In general, any feature can be made active. Here, we have illustrated
how a simple checking constraint can be implemented, but many other
uses are possible.(*) One caveat is in order at this point: to maximize
the flexibility of this mechanism, the feature goal is allowed to be
non-deterministic (and, hence, has_feature as well).
However, a current limitation is that active features introduced by
addFeature (as opposed to at lexical-insertion time) are
forced to be deterministic.
For completeness, there is a rather obscure variant of
goal/2:
| (y) |
goal(+Feature,lambda(-X,+Goal))
|
(See the lexical entry for the noun it shown in (n) for an example.)
Here, X will be bound at call-time to the features that
follow the active feature in question. Note X will be
supplied as an open list. This variant is not supported and will be
deleted in a future release. No documentation beyond this note is
supplied.
References: addFeature
(*) Simple exercise for the reader. How do you cancel a simple
feature, i.e. one like apos that's just an atom?
addFeature(+F,+-X)
|
Adds either a list of features
F1,..,Fn
or just a single feature F to constituent X
|
For the purposes of feature lookup, i.e. has_feature, the
convention adopted here is that features appended using
addFeature will supercede pre-existing ones. This
behaviour allows features to be updated or overridden as necessary.
Example:
Suppose features f(1), f(2) and
f(3) are added to [NP] (in the given order):
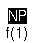 |
|
addFeature(f(2),[NP]) |
|
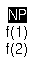 |
|
addFeature(f(3),[NP]) |
|
 |
| (a) | (b) | (c) | ||||||
| Goal | Result/Bindings | |
| (d) | [NP] has_feature f(X) |
Succeeds once / X = 3 |
| (e) | [NP] has_feature f(1) |
Succeeds once / None |
| (f) | [NP] has_feature f(2) |
Succeeds once / None |
| (g) | [NP] has_feature f(3) |
Succeeds once / None |
(See also the example from has_feature.)
Note: addFeatures([f(1),f(2),f(3)],X) is just a more
efficient way of stating:
... addFeatures(f(1),X), addFeatures(f(2),X), addFeatures(f(3),X), ...References:
has_feature
+X has_id -V
|
V is the unique id that identifies constituent
X. The id is implemented as a variable and care should be
taken not to instantiate or bind it to another variable.
|
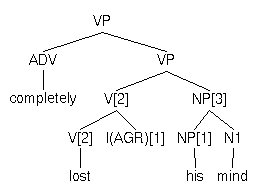
highestSegment(+X)
|
Holds if nothing has been adjoined to X. If
adjunction to X has taken place, holds only when
X is the highest or topmost segment.
|
Example:
 |
| (a) |
| Goal | Result | |
| (b) | highestSegment([VP completely [VP lost his mind]]) |
Succeeds |
| (c) | highestSegment([VP lost his mind]]) |
Fails |
| (e) | highestSegment([ADV completely]) |
Succeeds |
| (d) | highestSegment([NP [NP his][N1 mind]]) |
Succeeds |
References: Implementation Notes
lowestSegment(+X)
|
X must be the lowest or bottommost segment of an
adjunction structure.
|
Note: unlike highestSegment/1, lowestSegment(X)
does not hold if there has been no adjunction to X.
Example:
|
| (a) |
| Goal | Result | |
| (b) | lowestSegment([VP completely [VP lost his mind]]) |
Fails |
| (c) | lowestSegment([VP lost his mind]]) |
Succeeds |
| (e) | lowestSegment([ADV completely]) |
Fails |
| (d) | lowestSegment([NP [NP his][N1 mind]]) |
Fails |
References:
lowestSegment/2
/ highestSegment
/ segmentOf
/ Implementation Notes
agreeAGR(+-X,+-Y)
|
Holds if constituents X and Y agree.
The agreement feature is agr(AGR), where AGR
is the value. Where applicable, the value will be updated
to reflect the agreement.
The variant agreeAGR1/2 is an agreement checker.
No updating of agreement values will be carried out.
|
Agreement Values:
The agreement feature agr(AGR) has a slot
AGR which may be filled by an agreement value.
Agreement values must have one of the following forms:
| Form | Comment | |
| (a) | [+P,+N,+G] |
where P, N and G
represent person, number and gender values:
|
| (b) | not([+P,+N,+G]) |
agrees with everything except [P,N,G]. |
| (c) | [[+P1,+N1,+G1],..,[+Pn,+Nn,+Gn]] |
|
agrees with
[P1,N1,G1]
through to
[Pn,Nn,Gn]. |
||
| (d) | not([[+P1,+N1,+G1],..,[+Pn,+Nn,+Gn]]) |
|
agrees with everything except
[P1,N1,G1]
through to
[Pn,Nn,Gn]. |
||
| (e) | [] |
The empty list [] agrees with anything. |
| (f) | -V |
V is a variable. This is equivalent to
[]. |
For example, consider verb agreement values for English:
| Examples | Form | Agreement Value | |
| (g) | eat, die, flow | Base (infinitival) | not([3,[sg,m],[]]) |
| (h) | eats, dies, flows | 3rd person singular present | [3,[sg,m],[]] |
| (i) | ate, eaten, died, flowed | Past | [] or _ |
| (j) | am | 1st person singular present | [1,sg,[]] |
| (k) | was | 1st and 3rd person singular past | [[1,3],[sg,m],[]] |
| (l) | are, were | 2nd person plus 1st and 3rd person plural | not([[1,3],[sg,m],[]]) |
Examples:
Subject-verb coindexation and agreement:
| (m) | agreeAGR([NP John],I(AGR)t[1])
|
||
 |
|
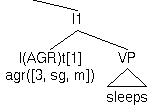 |
|
| (n) | agreeAGR([NP they],I(AGR)t[1])
|
||
 |
|
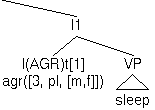 |
|
| (o) | agreeAGR([NP we],I(AGR)[1])
|
||
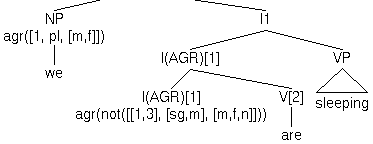 |
|
 |
|
References: agreeAGR/4
/ Implementation Notes
agreeAGR(+-X,+FX,+-Y,+FY)
|
Holds if constituents X and Y agree with
respect to the agreement features FX and
FY. Where applicable,
FX and FY will be
updated to reflect the agreement.
|
By convention, agreeAGR/2 assumes that the agreement
in each constituent is encoded as agr(AGR). The variant
agreeAGR/4 allows the caller to name another feature
to hold an agreement value.
There are two constraints that must be observed:
FX and
FY must have arity 1, i.e. be of form
f(AGR).
FX and
FY must be declared as agreement features
unless they refer to agr/1. The declarations should be
made using using agr_feature/1 as follows:
agr_feature(FX).
agr_feature(FY).
Example:
In the French implementation, we make use of an extra agreement
feature agr1/1 to do the gender agreement. For example:
| (a) | Mariei lit sai livre |
| (b) | *Marie lit sa livre |
| Maryi reads heri book |
In the lexicon, we have:
agr_feature(agr1(_)). ... lex(marie,n,[a(-),p(-),agr([3,sg,f])]). lex(livre,n,[a(-),p(-),count(+),agr([3,sg,m])]). ... lex(son,n,[morphC(gen),agr1([3,[sg,m],m]),agr([3,[sg,m],[]]),a(+),p(-)]). lex(sa, n,[morphC(gen),agr1([3,[sg,m],f]),agr([3,[sg,m],[]]),a(+),p(-)]).Hence:
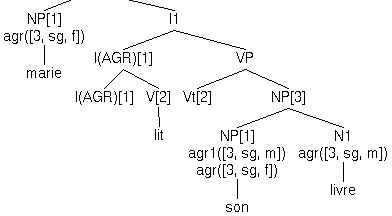 |
| (c) Marie1 lit son1 livre |
References: agreeAGR/2
intersectAGR(+-X,+AGR)
|
Holds if constituent X has a feature
agr(AGRX) such that the value
AGRX agrees with
AGR. AGRX will be updated to
reflect the agreement. Note: the value AGR is not
updated.
|
Example:
In English noun phrases, certain classes of nouns can stand alone without determiners. For example, proper names like John, or plural count nouns like boys as in boys boarded the train, or mass nouns like water as in water flows downhill.
Let us write a predicate nonDet(N) that holds if a noun
N can occur without a determiner. We will make use of the
agreement feature plus a count feature. Count nouns will have the
feature count(+), and mass nouns will have
count(-). Also, assume proper names are without
count/1:
noDet(N) :- \+ N has_feature count(_). % proper names noDet(N) :- N has_feature count(-). % mass nouns noDet(N) :- N has_feature count(+), intersectAGR(N,[[],pl,[]]).Here,
intersectAGR is used to pick out the plural count
nouns. Note the agreement value of the noun will be updated. Hence,
noDet will restrict the value of sheep in (a) to
plural only, but not (b):
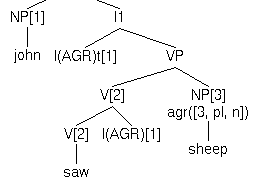 |
 |
| (a) John saw sheep | (b) John saw the sheep |
Reference: agreeAGR/2
coindex(+-X,+-Y)
|
Coindexes constituents X and Y.
|
Indices are encoded using the feature index(I) where
I represents the slot holding the actual index
value. Coindexation will unify index values. If the feature
index(I) is not already present in either or both
constituents, coindex will add it before unifying
index values.
Example:
In the following example, the (unindexed) subject John in (a)
is coindexed with inflection, I(AGR)t, which already has
been assigned the index 1 through head movement. The result of
coindex([NP John],I(AGR)t)is shown in (b). Here, John has acquired an index feature with the same value as
I(AGR):
 |
|
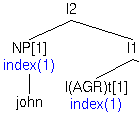 |
| (a) | (b) |
coindex can be defined using the predicate
index/2 as follows:
coindex(Item1,Item2) :- index(Item1,I), index(Item2,I).Reference:
index
index(+-X,-I)
|
Gives constituent X an index feature if it doesn't
already have one. I reports the value of the index.
|
Indices are represented by the feature index(I) where
I is the value of the index. The predicate
index/2 checks to see whether this feature is present. If
so, I is returned. If the feature is missing,
the constituent is indexed by adding the feature to its feature set.
Examples:
In (a), index([V sleeps],I) will succeed with
I bound to 2.
In (b), index([NP John],I) will assign a new index
feature to John, as shown in (c), and report the value of the
feature - in this case - 1:
|
|
Note: index is used to define coindex.
Reference: coindex
/ Implementation Notes
link(+-X,+-Y)
|
Imposes the constraint that constituents X and
Y have the same index if they both should become indexed.
|
link is the "lazy" counterpart of
coindex. These two predicate operate identically when
X and Y are already indexed, i.e. when they
already possess the feature index(_). However, if either or
both of the constituents aren't indexed, coindex will
fill in any missing index features (and then coindex), whereas link
doesn't assign an index feature, but waits until both constituents are
explicitly indexed before coindexing them.
Reference: coindex
/ Implementation Notes
|
Internal Structure |