

|
Batch Jobs
|
 |
|
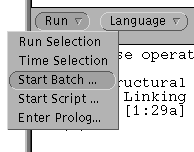
| Create a Batch PAPPI History File |
| Processing the PAPPI History File |
.xpl (Example) file.
Name it batch.xpl in the same directory as the PAPPI
executable.
"A Course in GB Syntax" BY LASNIK AND URIAGEREKA THE THETA-GRID AND X-BAR THEORY [1:4a] John slept [1:4b] John hit Bill [1:8a] *John slept Bill [1:8b] *John hit ... BINDING CONDITIONS AT LF? [6:64a] *He[i] likes everyone that John[i] knows [6:64b] Everyone that John[i] knows he[i] likes % Original: At LF. Problematic: Argues for adjunction to IP [6:65a] John likes every picture of himself [6:65b] Every picture of himself[i] John[i] likes % Original: At LF. Problematic: ditto. |
Here, we use a copy of l&u.xpl.
batch.xpl in a special mode. The history will contain
additional information (compared to using the Run Batch
button from the Run menu). In particular, the run time
and the various counts for each parser operation are also
reported. For example:
 |
Also, the start and completion times of the run are displayed in the history and the terminal window in which PAPPI was started. For example:
CPapp Please wait. Loading defaults... Start: Thu Aug 6 12:07:24 1998 End: Thu Aug 6 12:15:31 1998 |
Save History.. button in
the History menu:
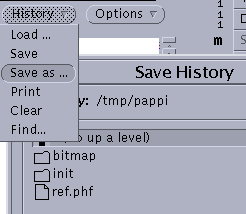
Choose an appropriate .phf (PAPPI History File) file
name.
more ~/.pappi
alias times grep "'Time taken:'" '\!*' "|" awk "'{"s += '$4'} "END {print NR, s, s/NR}'"
alias level1 "egrep -e '^content: (Parsing|LF|Parse blocked by)' \!* > /tmp/s"
alias level2 "egrep -e '^content: (Parsing|LF|Theta C|Condition A|Control|FI:|Parse PF|Assign S|Expletive L)' \!* > /tmp/s2"
alias levels "level1 \!* ; level2 \!*"
alias stimes grep "'Time taken:'" '\!*' "|" awk "'{"print '$4'} "' | sort -n"
alias reflevels "level1 \!* ; level2 \!* ; mv /tmp/s /tmp/t ; mv /tmp/s2 /tmp/t2"
alias compare1 "diff /tmp/s /tmp/t"
alias compare2 "diff /tmp/s2 /tmp/t2"
alias compare2c "diff -c /tmp/s2 /tmp/t2"
|
times
times new.phf 335 351.89 1.05042 |
indicates that 335 sentences were processed in
new.phf. Total CPU time for the batch job was just under
6 minutes and the average time per sentence was just over a second.
stimes
stimes new.phf 0.01 0.01 0.03 0.04 ... 8.93 10.97 29.54 115.02 |
reflevels, levels, compare1 and
compare2
reflevels to extract and
store away the results of the run.
levels to extract the results.
compare1 will do a first level diff on the results
with respect to grammaticality.
compare2 performs a more in-depth
comparision to also include the behaviour of each parser
operation.
(Assume reference build has been run and the history saved in ref.phf.) reflevels ref.phf (Assume new build has been run and the history saved in new.phf.) levels new.phf compare1 (No output. All the sentences have the same number of parses.) compare2 214c214 < content: Theta Criterion 6 2 D-structure Theta Condition 2 2 Case Filter 52 6 Case Condition on ECs 6 6 --- > content: Theta Criterion 2 2 D-structure Theta Condition 2 2 Case Filter 10 2 Case Condition on ECs 2 2 (Here, the new implementation differs from the old in detail. For example, the Theta Criterion was called 6 times instead of twice.) |
compare2c
compare2c is just like compare2 with the
-c option. Using three lines of context, may provide a
little more information:
compare2c *** /tmp/s2 Thu Aug 6 13:30:28 1998 --- /tmp/t2 Thu Aug 6 13:30:07 1998 *************** *** 211,233 **** content: Parsing: [1:30c] I wanted the bus to arrive on time content: LF (1): content: LF (2): ! content: Theta Criterion 6 2 D-structure Theta Condition 2 2 Case Filter 52 6 Case Condition on ECs 6 6 |
Here, we see that the difference occurs when parsing sentence [1:30c].
|
Batch Jobs
|