
|
Features
|
ParsePF
|
| Components:
| Example: John can't sleep
|
ParsePF represents the first stage of parsing in the
PAPPI system. It receives as input the sentence to be parsed, i.e. a
sequence of words, and performs lexical analysis to produce as its
output a corresponding sequence of base-level or zero-level
constituents (ZLSS).
These base-level constituents will be in turn fed as input to the
second stage of parsing, namely ParseSS. This
level performs standard phrase structure analysis to construct the
corresponding phrase structure tree representations at S-structure.
For example, ParsePF transforms a sentence like John
can't sleep into the following sequence of zero-level constituents:
[N John][V$[neg] can][V
sleep]. Within ParsePF, the transformation
is broken down into a series of smaller stages, as shown in the
diagram above.
ParsePF.
 |
Basically, the input consists of just words separated by spaces. However, there are a few embellishments:
(..) will be ignored.
%) is the comment character. Rest
of line is ignored.
*) are ignored.
. ? , ! " ' <newline> <tab> <space>
are word delimiters. All other characters except for $
and [..] are considered to be part of the
word.
ParsePF, except in the case of the single quote character
(') which functions both as a delimiter and as the
beginning of the next word. For example, John's becomes:
john 's
[..] immediately following a word can
be used for coindexation. For example, as in:
John[i] thought that he[i] won
john$[add(index(I))] thought that he$[add(index(I))] won
add/1 forces
parsePF to assign a feature index/1 with the
same variable (I) to both John and he.]
Note, empty square brackets ([]) can also be used to
exclude a word from coindexation. For example, it$[]
translates into:
it[add(noCoindex)]
noCoindex is a feature used by Free
Indexation defined in the principles file.]
If caseFoldInput holds,
words will be lowercased. By convention, this is set in the lexicon
file. So the preprocessor turns John into the Prolog atom
john, not 'John'. To leave case unchanged,
use the following declaration instead:
no caseFoldInput.
$) can be used in the sequence
word$translation to restrict word lookup to use the
lexical entry for word that has feature
eng(translation). For example, in the Japanese
implementation, specifying katta$buy in the input
string eliminates unwanted multiple parses.
References: Implementation Notes
Expand ContractionsExpand Contractions uses simple
contraction rules defined in the lexicon to `chop' or split up words
into their components. For example, the following two rules can be
used to derive can not and would not from can't
and wouldn't, respectively.
contraction([],can,'''t',[can,not]). contraction([],X+n,'''t',[X=morph(_,_),not]).Similarly, the following two rules simply stipulate that 'd and 've should be expanded into would and have, respectively.
contraction([],'''d',[would]). contraction([],'''ve',[have]).Both
contraction/3 and contraction/4 are
examples of simple string manipulation rules. That is, Expand
Contractions does not produce lexical categories, nor does it
take them as input. Note that this means such rules cannot make use of
general lexical features except under a very limited set of
circumstances concerned with stem recognition.
In general, contraction rules will apply optionally. That is, PAPPI
will try both the possibility of applying a contraction rule or
letting the input word go through unchanged. A special
blockContraction declaration can be used on a
word-by-word basis to inhibit contraction processing. For more details
on the format of the rules, see the documentation on the predicate contraction:
 |
| (a) Turning on Trace Contractions |
(Alternatively: it can be activated using the setup option
tracingContractions.)
For example, here is the contraction mechanism at work on the Japanese sentence Taroo-ga hihansareta:
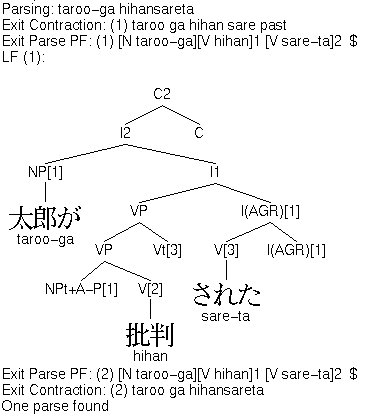 |
(a) Tracing Expand Contractions
|
Here, Expand Contractions produces two candidate
strings. In the first one, prefixed by Exit
Contraction: (1), the verb complex hihansareta is
broken down into the suru-taking verb stem (hihan),
followed by the passive form of suru (sare) to be
modified by the past tense morpheme (-ta). This analysis
subsequently leads to a successful parse. The second candidate string
is the one where no contraction rule has applied.
References: contraction
/
blockContraction
Expand Contractions HookExpand Contractions but before Lookup
Words. Initially, expandContractionsHook/2 is
defined to be a null stage as follows:
expandContractionsHook(Words,Words).See the Turkish implementation for an example of how to extend
expandContractionsHook/2 to handle noun-noun compounding.
Lookup Words.
Example constraints, as described above in the Input
Word section, generally pass through Expand
Contractions unscathed. Hence, the format of the words
presented as input to Lookup Words will be largely
unchanged. However, there is a special provision for compound words
formed either in Expand Contractions or
expandContractionsHook.
The following three compound forms are also valid:
merge(M,Word).
This structure is left-recursive. M is either another
instance of merge/2 or a simple word.
mergeR(Word,M).
This structure is right-recursive. M is either a simple
word or another instance of mergeR/2.
mergeRC(M1,M2).
M1 and M2 are both
instances of mergeR/2. This is used in multiple
compounding.
Lookup WordsLookup Words. Each word is processed
as follows:
lexicon(Word,C,Fs)
C is the category label and Fs is the list
of lexical features associated with Word.
The behaviour of Lookup Words is determined by the
outcome of lexical lookup:
[C
Word] is formed (except in the case of markers to be described
below).
ParsePF will fail for the
whole sentence.
ParsePF becomes non-deterministic. In other words,
ParsePF will produce multiple outputs on bracktracking.
Markers
If the word is a marker, i.e. C = mrkr, no
category [mrkr Word] is formed by Lookup Word.
In PAPPI, markers are special elements appearing in the input that do not project structure like regular categories. Instead, markers are realizations of feature elements that are attached to regular categories.
For example, in the English implementation, of as in:
(a) his picture of Maryis encoded as the realization of genitive Case. Following Knowledge of Language[Chomsky,86], we assume that the heads picture and proud assign genitive Case to the complement NP Mary. In other words, rather than positing a complement PP headed by of in both cases, we get the following two (simpler) parse fragments instead:
(b) proud of Mary
 |
 |
| (a) his pictures of Mary | (b) proud of Mary |
The lexical entry for of is as follows:
lex(of,mrkr,[right(np,case(gen),[])]). % object genitive CaseHere, the marker feature
right/3 states that of
attaches as a feature case(gen) to the NP on the right.
In general, the possible elements to which marker can attach must be
declared using the predicate relevant(C), where
C is a category label. For example, for English, we have:
% relevant for marker constraints relevant(n). relevant(v).Non-relevant categories are ignored or skipped-over for the purposes of feature attachment.
The following table specifies the possible marker features. Each
lexical entry for a mrkr item must contain a marker
feature. Generally, for each marker feature, C will be a
category label, F a feature to be matched and
A a feature to be added to the matching relevant item.
(The possible forms for F and A are defined
later in separate tables):
| Marker Feature | Description |
left(C,F,A)
|
Marks X, the relevant element of category
C to its left. X must satisfy feature
constraints F. If the match is successful, the features
given in A are added to X. If the match is
unsuccesful, Lookup Word fails locally.
Example: The English possessive marker 's is defined as follows:
lex('''s',mrkr,[left(n,[not(morphC(_)),case(gen)],[])]).
The possessive marker is the realization of genitive Case for those
nouns not already morphologically marked as genitive (e.g. possessive
personal pronouns like his).
|
right(C,F,A)
|
Marks X, the relevant element of category
C to its right. X must satisfy feature
constraints F. If the match is successful, the features
given in A are added to X. If the match is
unsuccesful, Lookup Word fails locally.
Example:
The infinitival marker to matches with the (base form) verb
to its right, and adds the feature lex(to,mrkr,[right(v,morph(_,[]),inf([]))]). % infinitival markerSee also the of-insertion example described earlier. |
leftec(C,F,A,G,_)
|
As for left(C,F,A) except in the case
where the relevant element immediately to its left is not of category
C. A new empty category with label C is
created and inserted immediately to its left. The features of this
new category is given by the goal G, which must of the
form goal(Goal,Fs) where Goal is a call to
a user-specified predicate that computes a list of features
Fs.
Example:
In the Turkish implementation, the plural marker normally marks a
singular noun to its left. In the case of a plural-marked adjective
like k���kler (small-plr), the following rule produces
lex(plr,mrkr,[leftec(n,[agr([3,sg,[]])],override(agr([3,pl,[]])),
goal(emptyNFs(Fs),Fs),_)]).
emptyNFs/1 is defined by:
emptyNFs(Fs) :- mkFs([ec(_),a(-),p(-),grid([],[]),agr(_),noECP(lf), case(_),theta(_)],Fs).Note: the agr(_) feature will be instantiated by
override(agr([3,pl,[]])).
|
rightec(C,F,A,G,_)
|
As for right(C,F,A) except in the case
where the element immediately to its right is not of category
C. A new empty category with label C is
created and inserted immediately to its right. The features of this
new category is given by the goal G, which must of the
form goal(Goal,Fs) where Goal is a call to
a user-specified predicate that computes a list of features
Fs.
Example: From the Turkish implementation, the noun relativizer -ki marks the noun to its right and allows it to take a locative complement: lex(ki_mrk,mrkr,[rightec(skip(n,[a]),[not(a(+)),not(p(+))], [modify(grid(X,_),grid(X,[location]))], goal(emptyNFs(Fs),Fs),_)]).Note: the definition of emptyNFs/1 is given in the
example for leftec.
|
F specifies the pre-conditions for marker
attachment in left/right/leftec/rightec. The elements in
F are unified with the features of the candidate item
according to the following rules:
| Constraint | Description |
[]
|
matches any item. |
F
|
F a feature. Item must contain a feature
unifiable with F.
|
not(F)
|
F a feature. Item must not contain a
feature unifiable with F.
|
[F1,..,Fn]
|
Item must satisfy constraints
F1 through Fn.
|
if(F)
|
where F is a constraint. If F
matches, the add feature portion, A is carried out. If
there is no match, A is skipped.
|
eval(F,G)
|
F a feature, and G a
goal. Item must contain a feature unifiable with F and
goal G holds.
|
eval(if(F),G)
|
F a feature, and G a
goal. If item contains a feature unifiable with F,
goal G must hold. Otherwise, G is skipped.
|
Example:
lex(gen,mrkr,[leftec(n,[eval(if(morphC(X)),(X==nom))],override(morphC(gen)), goal(emptyNFs(Fs),Fs),_)]).Here, the Turkish genitive Case marker instantiates the
morphC(gen) feature of the item immediately to its left.
However, if the feature morphC is already present on the
item, only nominative Case can be overridden by genitive Case.
[A note on leftec/rightec: Consecutive
leftec markers will not introduce multiple empty
categories. For instance, in the Turkish implementation,
siyahlar� (black-pl-acc), to be interpreted as "the black
ones", is defined as being an adjective followed by the plural and
accusative Case markers. Both of these are
leftecs. However, only one empty noun marked for plural
number and accusative Case should be generated. Hence, for empty noun
generation, PAPPI automatically batches up consecutive
leftec and rightec markers.]
A in left/right/leftec/rightec
specifies the features to be added to the matching item. Note that
feature instantiation can be carried out during the matching
phase. The following table gives the possible ranges of values for
the add features:
| Add Feature | Description |
[]
|
do nothing. |
A
|
A a feature. A is added to
the feature list for the matching item if there is no feature already
in item that unifies with A.
Note: compare with add features |
new(A)
|
A a feature. A is added to
the feature list for the matching item provided feature is not
already present.
Note: in cases where feature |
override(A)
|
A a feature. A is added to
the feature list for the matching item.
Note: in contrast with |
[A1,..,An]
|
Features A1 through
An are added to the matching item.
|
modify(F,A)
|
F and A features. Matching
item must have a feature unifiable with F. If so,
A is added to the item.
Example:
In the Japanese implementation, the past tense marker modifies the
lex(past,mrkr,[left(v,[],[modify(morph(X,_),morph(X,past(+))), suffix(W+ta,K+a4bf)]),prefix(W,K)]). |
modify(F,A,G)
|
G a goal, and F and
A features. Matching item must have a feature
unifiable with F. If so, goal G must hold and
A is added to the item.
|
suffix(S)
|
S a simple atom or a concatenation
expression of the form X+Y where X and
Y are simple atoms. The word for the matching item is
suffixed with S. If S is not simple,
X and Y are first concatenated to form a
simple atom.
|
suffix(S,K)
|
As for suffix(S) except
that K is concatenated onto the end of the
value of the k(_) feature for the matching item.
As in the case of S, K may be simple or a
concatenation expression.
Example:
In the Japanese implementation, the nominative Case marker
lex(ga,mrkr,[left(n,[],[morphC(nom),suffix(ga,a4ac)])]).See the earlier example of the past tense marker for an example where S and K are non-simple.
|
Summarizing, markers are general devices that may be used anywhere where there are words or morphemes that may be simply reduced to features attached to lexical items. See the Hungarian and Turkish lexicons for more examples of how morpheme markers are used in conjunction with the contraction mechanism.
W1..Wn, n>1, each
component Wi is matched against
the lexicon using:
Eachlexicon(Wi,C,Fs)for1<=i<=n
Wi must share the same category label
C. A compound zero-level category is formed:
Each compound structure must also obey the following rules:[C Word]whereWordis1,..,Wnconcatenated.
merge(..merge(W1,W2)..,Wn),
W1..Wn must all share the same
the theta-grid feature, grid/2.
The features of the aggregate is simply determined as the union of the
features of its components, except in the case of the
k(_) feature, which is formed by concatenating all
of the component k(_) features.
Note: This form of compounding is currently only used by the Chinese implementation for Serial Verb Constructions (SVC).
Two other declarations must also be provided:
The supplied definition must return a single list,
Example:
The Turkish implementation uses mergeR(W1,..mergeR(Wn-1,Wn)..),
the features of the aggregate is basically given by the features of the head
W1.
mergeRFeatures(List), where List is a
list of components features to be accumulated.
mergeRFeaturesComposeHook(List,List'), where
each element of List contains the list of features
nominated in mergeRFeatures/1 for
W1 through Wn.
List',
will be appended to the list of features for the aggregate.
mergeR plus the following
definitions to produce a composite eng(_) feature for
noun-noun compounding:
mergeRFeatures([eng(_)]).
% takes [[eng(E1)],[eng(E2)],..,[eng(En)]]
% returns [eng(E1 E2 .. En)]
mergeRFeaturesComposeHook(List,[eng(Eng)]) :-
composeEng(List,Eng).
composeEng([[eng(E)]],E) :- !. % red
composeEng([[eng(E1)]|Fs],E) :-
composeEng(Fs,E2),
concatAtoms([E2,' ',E1],E).
mergeRC(M1,M2), where
M1 and M2 are
instances of mergeR/2,
the features of the aggregate is basically given by the features of
the head of the sub-compound M1. The rest of
the details are identical to that for mergeR/2.
ParsePF HookParsePF Hook is initially defined to be a null
stage. It may be overridden as needed by individual lexicons to
perform additional transformations on the input. It's initial
definition is as follows:
parsePFHook(PF,PF).For instance, see the Hungarian or Japanese lexicon for examples of how
ParsePF Hook can be redefined to fill in default lexical
feature values.
ZLSSParsePF is a sequence of zero-level
categories with markers resolved into features that attach to
relevant lexical or specially-introduced empty categories.
|
Features
|