We document here the major lexical interfaces to the implemented system, which currently runs in SWI-Prolog, and generally follows its syntax.
Summary: named heads are given as a list to run/1.
Named heads must be defined in grammar.pl
Merge fires and assembles these heads (in order) into a single
syntactic object (SO). That SO can be read/interpreted at the C-I
interface and also Spelled out.
Example:
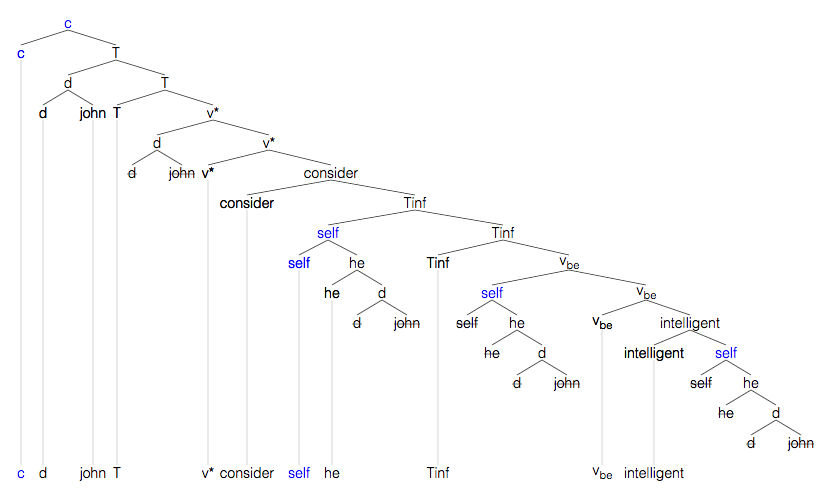
Named heads: [john, d, he, self, intelligent, v_be, 'Tinf',
consider, 'v*', 'T', c]
Spell out: John considers himself to be intelligent
SO:
[c[c][T[d[d][john]][T[T][v*[d[d][john]][v*[v*][consider[consider][Tinf[self[self][he[he][d[d][john]]]][Tinf[Tinf][vbe[self[self][he[he][d[d][john]]]][vbe[vbe][intelligent[intelligent][self[self][he[he][d[d][john]]]]]]]]]]]]]]]
SO (tree) (strikethrough indicates unspelled heads):
A separate glossary of relevant terms, highlighted in

At the browser user interface, the run/1 command is sent
via the
Example:
[mary, d, see, 'v*', [john, d], 'Tpast', c]is the list of names of heads necessary to assemble the syntactic object (SO) for the declarative sentence John saw Mary. Each name is a Prolog
Equivalently, in the Terminal user interface, the run/1 command can be typed directly at the Prolog prompt (?-).
(base) Machine$ swipl Welcome to SWI-Prolog (threaded, 64 bits, version 9.0.4) SWI-Prolog comes with ABSOLUTELY NO WARRANTY. This is free software. Please run ?- license. for legal details. For online help and background, visit https://www.swi-prolog.org For built-in help, use ?- help(Topic). or ?- apropos(Word). ?- [mm]. true. ?- run([mary, d, see, 'v*', [john, d], 'Tpast', c]).
mkSO(Name, Head) takes the
Example:
?- mkSO('Tpast',SO).
SO = [Tpast].
'Tpast' is the quoted To obtain the features of the head, mkSO/2 will call the predicate features/4 defined in grammar.pl.
(Note: pretty printing of syntactic objects is defined in portray.pl.)
Deep dive: in this implementation, SOs are represented by a structure so(LBL,uFs,iFs,Fs,SOs) of ariy 5. LBL = label. uFs, iFs, Fs = Prolog lists of uninterpretable, interpretable and implementation-specific features, respectively. SOs is a list of sub-constituents. Do not rely on this encoding, things have changed substantially and will change even more substantially in the future.
features(C,UFs,IFs,Fs) defines for head name C three lists of features.
Example: In the current implementation, 'Tpast' is the name of the past tense variant of the T head.
?- features('Tpast',UFs,IFs,Fs).
UFs = [f(phi, _, _)],
IFs = [],
Fs = [ef(_, _), occ(_), id(_)].
The past tense head has uninterpretable ɸ-features, no interpretable
features, and several bookkeeping features.
Generally, featural properties are listed in grammar.pl. Here are the definitions for matrix C, declarative (named c) and interrogative (named c_Q).
% matrix declarative features(c,[],[],[id(_),phase(_)]). % matrix interrogative features(c_Q,[f(wh,_),f('T',_)],[f(scope)],[ef(_,_),id(_),phase(_)]).Both c and c_Q are Phases, and have feature phase(_) that mark the local limit for Merge. We assume the Phase feature is not read at the C-I interface, nor is it valued by probe-goal, so it's neither interpretable nor uninterpretable.
(For pretty-printing, Phase heads are marked in blue in the browser user interface trees.)
Interrogative C, named c_Q, is a probe with an uninterpretable Wh feature that must be valued, and it also possesses an interpretable scope feature. The probe will find goal wh-DPs with an interpretable wh feature. Interrogative C also has an edge feature that permits a wh-NP to raise here (and possibly spell-out here). (In later theories such as Box theory, no Internal Merge operation is necessary.) Finally, interrogative C has an uninterpretable T feature (forced by the adoption of Pesetsky & Torrego). In Who saw John?, interrogative C has both uninterpretable Wh and T simultaneously valued by subject DP who. By economy, this prevents T separately raising to interrogative C, which can value T (on C), from the wh-DP raising to value Wh on C. Otherwise, T in interrogative C will result in *Who that saw John? as an option, as T in C isobligatorily pronounced as that.
Deep dive: the bookkeeping features are all imperfections in the current implementation, and should be eliminated in future versions.
occ(_) is used to control spell-out. In the implemented theory, 'Tpast' may raise to C and be pronounced as that, following Pesetsky & Torrego. The lower occurrence of 'Tpast' is not pronounced. occ/1 keeps track of which occurrences may be pronounced.
id(_) is used an an unique identifier. In the probe-goal implementation, we sometimes need to uniquely identify which head is doing the valuing.
ef(_,_) is the Edge feature. It is not a feature to be read at the C-I interface, so it's not interpretable. It is not targeted by probe-goal, so it's not an uninterpretable feature either. It is placed here as it doesn't fit in either category. The fact that T has a surface subject position is really irreducible in the current theory.
Common nouns are divided into nRoot1/1 or nRoot2/1 or nRoot3/1 in grammar.pl. The difference between the three types is in terms of ɸ-features.
nRoot1/1 nouns are 3rd person singular nouns. Features are determined by the following line:
features(N,[f('D',_)],[f(phi,[3,sg,n],_)],[occ(_)]) :- nRoot1(N).
See also documentation of features/4 above.
Similarly, nRoot2/1 are 3rd person plural nouns.
features(N,[f('D',_)],[f(phi,[3,pl,n],_)],[occ(_)]) :- nRoot2(N).
nRoot3/1 nouns are unspecified for Number.
Examples of the three types are given below:
| nRoot1/1 | nRoot2/1 | nRoot3/1 |
|---|---|---|
| nRoot1(apple) | nRoot2(boxes) | nRoot3(fish) |
| nRoot1(man) | nRoot2(men) | |
| nRoot1(violin) | nRoot2(shelves) |
nRoot2/1 entries for nRoot1/1 nouns with regular plurals are not explicitly listed. A spelling rule that adds -s will be used to form the corresponding nRoot2/1 entry.
Phase heads are defined in grammar.pl to contain a feature phase that limits search. As it is not valued in probe-goal operations, the feature is not an uninterpretable feature. It is also not read at the C-I interface, so it is not an interpretable feature either. Hence, it is placed in the third feature list.
Examples:
% complementizers % matrix declarative features(c,[],[],[id(_),phase(_)]). % matrix interrogative features(c_Q,[f(wh,_),f('T',_)],[f(scope)],[ef(_,_),id(_),phase(_)]). % embedded declarative features(c_e,[f('T',_)],[f(theta,_)],[ef(_,_),id(_),phase(_)]). % wh-movement host, no scope feature features(c_eQ,[f(wh,_),f('T',_)],[f(theta,_)],[ef(_,_),id(_),phase(_)]). % embeddded interrogative features(c_Qe,[f(wh,_),f('T',_)],[f(theta,_),f(scope)],[ef(iF(wh),_),id(_),phase(_)]). % relative C features(c_rel,[f(rel,_),f('T',_),f(phi,_,_)],[],[ef(_,_),id(_),phase(_)]). % complementizer for features(for,[f(phi,_,_)],['T'],[occ(_),phase(_)]). % -self and possessive 's features(self,[f(case,_,_),f('N',_)],[f(theta,_)], [phase(_),release(_),occ(_)]). features('\'s',[f(case,_,_),f('N',_)],[f(phi,[3,_,_],_),f(theta,_)], [ef(unvalued_iF(theta),_),phase(_),occ(_)]).
Verbs are listed using vRoot/1, the single argument should be the base nonfinite form.
features(V,[],[],[occ(_)]) :- vRoot(V).
Deep dive: occ(_) is a bookkeeping feature used to control whether the occurrence of the verb is spelled out or not.
Spellout is part of Externalization (EXT), based on linear order, and not part of Narrow Syntax.
Basic algorithm: Look at the frontier of the SO as a list of heads. Ignore all heads marked by occ as not the highest occurrence (of that head). Let remaining heads be [h1, h2, .., hn].
Then proceed linearly through the list:
[This implies two passes for TNS to verb inflection, one to convert TNS to a morpheme, e.g. -ed, and one to convert the morpheme + head, e.g. -ed fall to fell. Maybe worth converting this to a single pass algorithm.]
Example: consider the frontier shown for the sentence John considers himself to be intelligent (at the top of this document).
[c, d, john, 'T', 'v*, consider, self, he, 'Tinf', vbe, intelligent]C, v* and D are not spelled out, conversion of T and Tinf into -s and to is applied, names are spelled with inital caps, and Accusative Case is turned into affix -acc.
[John, '-s' , consider, '-self', '-acc', he, to, be, intelligent]Affix hop:
[John, consider, '-s', he, '-acc', -self', to be, intelligent]2nd pass: consider + -s -> considers and he + -acc + -self -> himself etc.:
[John, considers, himself, to be, intelligent]
Certain heads never spell out.
no_spellout(d). % empty determiner
no_spellout(d_rel). % empty determiner (for relativization)
no_spellout(q). % empty wh-determiner
no_spellout(pro). % small pro and big PRO
no_spellout('PRO').
no_spellout('G'). % dyadic preposition G
Other spellout rules are language-particular and explicitly learned.
Inflection for spellout is controled by affix rules or explicitly listing exceptions (for irregular verbs).
Example: write has irregular forms when combined with morpheme -en or -ed(ɸ).
vRoot(write). spell_out(en,write,written). spell_out(ed(ɸ),write,wrote).
Note: ɸ in -ed(ɸ) is not used in the English implementation. Verbal suffixes are computed by realize_head/2.
realize_head/2 maps a single head onto a verbal inflectional morpheme. In the current implementation, T with tense features and (computed) ɸ-features generates the following ɸ-specific inflectional morphemes, -m, -re, -s, and -ed, in English.
Examples:
realize_head(t(pres,[1,sg],_),-m). % am realize_head(t(pres,[2,sg],_),-re). % are realize_head(t(pres,[3,sg],_),-s). realize_head(t(pres,[_,pl],_),-re). % are realize_head(t(past,[1,sg],_),-ed(sg)). realize_head(t(past,[1,pl],_),-ed(pl)). realize_head(t(past,[2,_],_),-ed(pl)). realize_head(t(past,[3,sg],_),-ed(sg)). realize_head(t(past,[3,pl],_),-ed(pl)).Note: NUM in -ed(NUM) is currently unused.
realize_head/2 is also used for auxiliary heads in English verbal system to impose a linear constraint on the output form of the next verb (after affix hopping).
Examples:
realize_head(prog,-ing). % be -ing eat -> be eating realize_head(perf,-en). % have -en eat -> have eaten realize_head(prt,-en). % be -en eat -> be eaten
In English, pronouns do inflect with Case. At Spell-out, non-nominative Case such as acc (Accusative) and obq (Oblique) are separate morphemes in this implementation.
Examples:
spell_out(acc,who,whom). spell_out(acc,he,him). spell_out(acc,she,her). spell_out(acc,they,them). spell_out(acc,i,me). spell_out(acc,'I',me). spell_out(acc,we,us). spell_out(obq,he,him). spell_out(obq,she,her). spell_out(obq,they,them). spell_out(obq,i,me). spell_out(obq,we,us).
In English, -self, a separate lexical head in this implementation, will combine with pronominals.
Examples:
spell_out(self,him,himself).
spell_out(self,her,herself).
spell_out(self,my,myself).
spell_out(self,you,yourself).
spell_out(self,you,yourselves). % plural
spell_out(self,our,ourselves).
spell_out(self,they,themselves).
spell_out(self,he,nospellout). % lexical gap
The last case indicates -self + he -> *heself.
Regular verbal spellout rules for English are also described using spell_out/3, summarized below.
Certain head bigrams cannot spell out at all. If generated, derivation will fail.
Examples:
block_heads(of,who_rel). % *of who block_heads(than,who_rel). % *than who
Certain head bigrams, e.g. personal pronouns in English, spell out specially.
[Need to explain why we have both spell_out/3 and realize_heads2/3 or collapse them.]
Examples:
realize_heads2(he,'\'s',[his]). % he + 's -> his realize_heads2(she,'\'s',[her]). % she + 's -> her realize_heads2(they,'\'s',[their]). realize_heads2(you,'\'s',[your]). realize_heads2(i,'\'s',[my]). realize_heads2(it,'\'s',[its]).Prolog notation: '\'s' is an atom. The escaped single quote is a single quote character inside '...'. So '\'s' is the unquoted atom 's. See atom in the glossary.
T in C spellout as that also uses realize_heads/3.
Example:
realize_heads(T,C,[that]) :- morpheme_withFs(T,'T'), type(C,c).
Examples: